
Scientific Computing and Data / AIR·MS (AI Ready Mount Sinai) / AIR·MS Data Modalities
AIR·MS Data Modalities
The AIR·MS platform proudly features the following Mount Sinai and public datasets. Our team is dedicated to continuously expanding our database with additional data modalities, striving to build a comprehensive, multi-modal research resource. To help you get started with the data, we offer Quick Start guides available here. Available Datasets (PHI = Protected Health Information, De-ID = De-Identified Information):
- Mount Sinai Data Warehouse (MSDW) OMOP De-Identified (De-ID) and Protected Health Information (PHI)
- Pathology Metadata (PHI)
- Mount Sinai Million Data (PHI and De-ID)
- Electrocardiogram (ECG) Metadata (PHI)
- Intensive Care Unit (ICU) Operational Datamart (PHI)
- Radiology Metadata (PHI)
- Echocardiography Metadata (PHI)
- Endoscopy Reports (PHI)
Public Datasets:
Mount Sinai Data Warehouse (MSDW) OMOP De-Identified (De-ID) and Protected Health Information (PHI)
The MSDW dataset leverages the OMOP Common Data Model. The data is comprised of clinical data extracted from Mount Sinai’s Epic Caboodle database and other ancillary systems. We offer both the identified (PHI) and de-identified (De-ID) versions of this data. 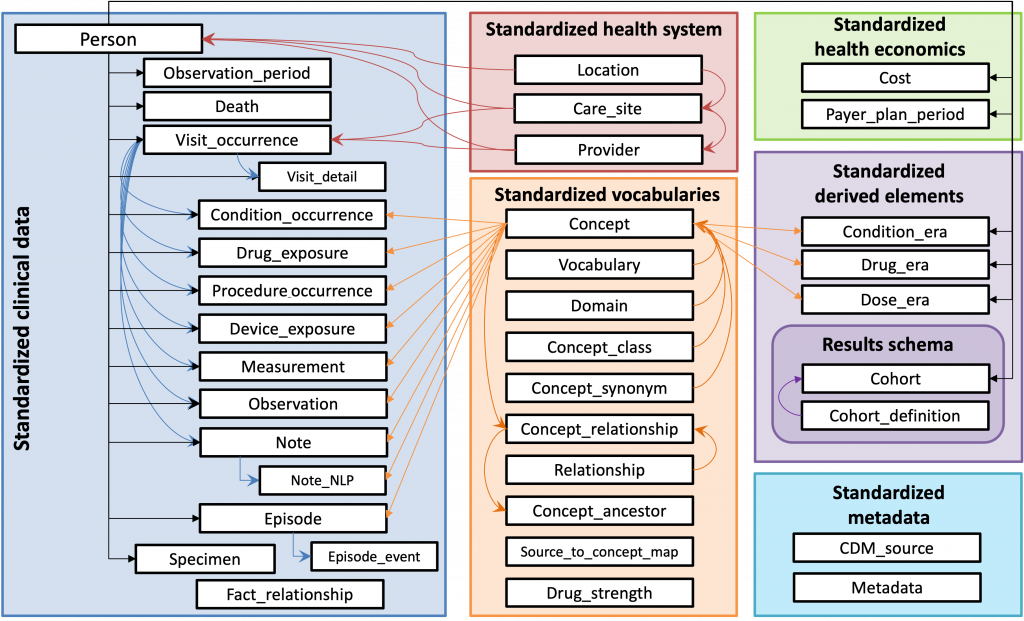
We offer both an identifiable and a de-identified version of the MSDW dataset in AIR·MS
MSDW OMOP identifiable (PHI) with extended attributes Current Status
Schema: CDMPHI Data snapshot from 09/10/2025 Unique patients: 12,521,239
| Table | Record Count |
| ATTRIBUTE_DEFINITION | 0 |
| CARE_SITE | 108,613 |
| CDC_RACE_ETHNICITY_XTN | 967 |
| CDM_SOURCE | 1 |
| COHORT | 6,100,000 |
| COHORT_DEFINITION | 3 |
| CONCEPT | 11,357,728 |
| CONCEPT_ANCESTOR | 101,072,304 |
| CONCEPT_CLASS | 453 |
| CONCEPT_RELATIONSHIP | 178,331,994 |
| CONCEPT_SYNONYM | 5,190,521 |
| CONDITION_ERA | 0 |
| CONDITION_OCCURRENCE | 224,124,347 |
| COST | 0 |
| DATABASECHANGELOG | 64 |
| DATABASECHANGELOGLOCK | 1 |
| DEATH | 49,797 |
| DEVICE_EXPOSURE | 0 |
| DOMAIN | 50 |
| DOSE_ERA | 0 |
| DRUG_ERA | 0 |
| DRUG_EXPOSURE | 241,235,148 |
| DRUG_STRENGTH | 3,003,619 |
| FACT_RELATIONSHIP | 169,049,038 |
| LOCATION | 13,822,023 |
| MEASUREMENT | 1,963,710,364 |
| METADATA | 0 |
| NOTE | 251,559,257 |
| NOTE_NLP | 0 |
| OBSERVATION | 538,781,648 |
| OBSERVATION_PERIOD | 12,561,446 |
| PAYER_PLAN_PERIOD | 0 |
| PERSON | 12,521,239 |
| PROCEDURE_OCCURRENCE | 355,906,745 |
| PROVIDER | 1,372,277 |
| PROVIDER_ATTRIBUTE_XTN | 788,610 |
| RELATIONSHIP | 730 |
| SOURCE_TO_CONCEPT_MAP | 0 |
| SPECIMEN | 0 |
| VISIT_DETAIL | 0 |
| VISIT_OCCURRENCE | 230,899,469 |
| VOCABULARY | 254 |
Note: Some of the standard OMOP tables contain extension fields (starting with the prefix ‘XTN’) which contain data outside of the OMOP standard data model. Many of these XTN attributes are based on data derived directly from EPIC (i.e. codes used in EPIC rather than the standardized OMOP codes), or attributes not currently contained in the OMOP standard.
MSDW OMOP de-identified (de-id) Current Status
Schema: CDMDEID Data snapshot from 10/20/2025 Unique patients: 12,008,581
| Table | Record Count |
| ATTRIBUTE_DEFINITION | 0 |
| CARE_SITE | 109,310 |
| CDC_RACE_ETHNICITY_XTN | 967 |
| CDM_SOURCE | 1 |
| COHORT | 3,739,597 |
| COHORT_ATTRIBUTE | 0 |
| COHORT_DEFINITION | 11 |
| CONCEPT | 11,382,893 |
| CONCEPT_ANCESTOR | 84,020,373 |
| CONCEPT_CLASS | 449 |
| CONCEPT_RELATIONSHIP | 175,957,371 |
| CONCEPT_SYNONYM | 5,190,383 |
| CONDITION_ERA | 0 |
| CONDITION_OCCURRENCE | 207,689,269 |
| COST | 0 |
| DATABASECHANGELOG | 60 |
| DATABASECHANGELOGLOCK | 1 |
| DEATH | 57,522 |
| DEVICE_EXPOSURE | 0 |
| DOMAIN | 50 |
| DOSE_ERA | 0 |
| DRUG_ERA | 0 |
| DRUG_EXPOSURE | 223,692,656 |
| DRUG_STRENGTH | 2,981,765 |
| FACT_RELATIONSHIP | 158,497,299 |
| LOCATION | 138,7824 |
| MEASUREMENT | 2,018,330,339 |
| METADATA | 0 |
| NOTE | 216,623,789 |
| NOTE_NLP | 0 |
| OBSERVATION | 398,593,907 |
| OBSERVATION_PERIOD | 12,091,204 |
| OMOP.TRACE | 0 |
| PAYER_PLAN_PERIOD | 0 |
| PERSON | 12,008,581 |
| PROCEDURE_OCCURRENCE | 331,740,865 |
| PROVIDER | 1,373,456 |
| PROVIDER_ATTRIBUTE_XTN | 787,290 |
| RELATIONSHIP | 730 |
| SCHEMA.METADATA | 0 |
| SLIDE_XTN | 2,397,874 |
| SOURCE_TO_CONCEPT_MAP | 0 |
| SPECIMEN | 0 |
| SURVEY_CONDUCT | 0 |
| VISIT_DETAIL | 0 |
| VISIT_OCCURRENCE | 208,717,628 |
| VOCABULARY | 237 |
Pathology Metadata (PHI)
The Pathology metadata aids researchers in the field of Computational Pathology. Researchers are able to query the metadata in combination with other linked data modalities to build a patient cohort, subsequently apply quantitative methods for the analysis of digital microscopy slides and relating the resulting statistical descriptors to patient outcomes. We are also working on making the digital slides available to researchers on Minerva HPC.
Current Status
Data Source: Powerpath Schema: CDMPATHOLOGY Data snapshot from 01/08/2025 Unique patients: 3,528,719
Note: Pathology reports are now available in AIR·MS and can be found in table ACC_RESULTS. The reports are broken up into sections (clinical history, final diagnosis, SNOMED coding, etc.) that can be identified by column PATH_RPT_HEADING_NAME. If you are looking for the full report, you can combine all records for with the same ACCESSION_2_ID into a single output. The column containing the free-text (ACC_RESULTS_FINDING) has been enabled with SAP HANA full-text search capabilities. Examples of how to use HANA full-text search are available in this tutorial notebook.
The following tables and attributes are available in AIR·MS:
ACCESSION
Number of records: 7,107,464
| Column Name | Comments |
|---|---|
| ACC_CATG | Case category |
| ACC_PROCESS_STEP_COMPLETED_DATE | Case finalize date / status update datetime |
| ACCESSION_2_ID | PowerPath unique case ID |
| ACCESSION_NO | Case number |
| BIRTH_DATE | Patient date of birth |
| CREATED_DATE | Case creation date |
| CURRENT_STATUS_ID | PowerPath unique identifier for a case status |
| FACILITY_CODE | Facility code |
| FACILITY_ID | PowerPath ID for the facility associated with the accession |
| FACILITY_NAME | Facility name |
| IMPORTED_CASE | One-character \”Y\” or \”N\” code indicating if the case was imported into PowerPath |
| LAST_UPDATE_DATETIME | Case finalize date / status update datetime |
| MED_REC_NO | Medical record number (EPIC MRN) |
| MRN_FACILITY_CODE | PowerPath ID for the facility that assigned the MRN |
| MRN_FACILITY_DESCRIPTION | Name of the facility that assigned the MRN |
| ORDER_NUMBER | Order number from the ordering system |
| PATIENT_AGE | The patient’s age on the case creation date |
| PATIENT_ID | PowerPath patient ID |
| PERSONNEL_2_FULL_NAME | Name of the pathologist who finalized the accession |
| PERSONNEL_2_ID | PowerPath ID for the pathologist who finalized the accession |
| PROCESS_STEP_DESCRIPTION | Case status name / description |
| VISIT_NUMBER | Encounter identifier |
ACC_ICD
Number of records: 3,548,815
| Column Name | Comments |
|---|---|
| ACC_ICD9_ID | PowerPath surrogate unique identifier for an ICD-10 code assigned to a case |
| ACCESSION_2_ID | PowerPath unique case ID |
| LAST_UPDATE_DATETIME | Case finalize date / status update datetime |
| MEDICAL_CODE | ICD-10 code assigned for billing |
| MEDICAL_CODE_ID | PowerPath surrogate unique identifier for an ICD-10 code |
ACC_SLIDE
Number of records: 14,241,494
| Column Name | Comments |
|---|---|
| ACC_BLOCK_ID | PowerPath unique block ID |
| ACC_BLOCK_LABEL | Specimen block identifier |
| ACC_PROCESS_STEP_COMPLETED_DATE | Case finalize date / status update datetime |
| ACC_SLIDE_ID | PowerPath unique slide ID |
| ACC_SPECIMEN_DESCRIPTION | Specimen source description |
| ACC_SPECIMEN_ID | PowerPath unique specimen ID |
| ACCESSION_2_ID | PowerPath unique case ID |
| BIOPSY | Boolean flag for 1 = biopsy, 0 = non-biopsy |
| COLLECTION_DATE | Specimen collection date |
| CONSULT_LABEL | Optional free text for slides of type \”consult\” |
| LAB_PROCEDURE_CODE | The procedure code |
| LAB_PROCEDURE_DESCRIPTION | The procedure description |
| LAB_PROCEDURE_ID | PowerPath unique procedure identifier |
| LAST_UPDATE_DATETIME | Case finalize date / status update datetime |
| RECV_DATE | Specimen received date |
| SLIDE_LABEL | Derived unique (business key) identifier for each slide |
| SLIDE_NO | Ordinal number of the slide from the specimen & block |
| SLIDE_TYPE | Whether the slide is stained, unstained or antibody/IHC |
| SOURCE_MATERIAL_LABEL | Derived unique (business key) identifier for each slide’s source specimen and block |
| SOURCE_REC_TYPE | Where the slide came from, either specimen or block |
| SPECIMEN_CATEGORY_ID | PowerPath specimen category ID |
| SPECIMEN_CATEGORY_NAME | The specimen category name |
| SPECIMEN_GROUPS_CODE | Specimen specialty code |
| SPECIMEN_GROUPS_ID | PowerPath specimen specialty ID |
| SPECIMEN_LABEL | Specimen identifier |
| TYPE | Whether the slide is consult or not consult |
ACC_RESULTS
Number of records: 31,193,765
| Column Name | Comments |
|---|---|
| ACC_RESULTS_FINDING | The text of the report section |
| ACC_RESULTS_ID | PowerPath unique identifier for each report section |
| ACC_RESULTS_REC_ID | sort order of result section on RTF |
| ACCESSION_2_ID | PowerPath unique case ID |
| LAST_UPDATE_DATETIME | Case finalize date / status update datetime |
| PATH_RPT_HEADING_ID | PowerPath result section heading on RTF |
| PATH_RPT_HEADING_NAME | PowerPath result section heading name |
ACC_SLIDE_IMAGESERVER
Number of records: 2,564,239
| Column Name | Comments |
|---|---|
| ACC_SLIDE_ID | PowerPath unique slide ID |
| ACC_SLIDE_IMAGESERVER_DESCRIPTION | The name of the Philips iSyntax slide image file |
| ACC_SLIDE_IMAGESERVER_ID | PowerPath unique identifier for a slide image |
| INTERNAL_SLIDE_ID | Identifier for the slide, also known as the \”barcode\” ID |
| LAST_UPDATE_DATETIME | Case finalize date / status update datetime |
| SCAN_DATE | The date on which the slide image was digitized |
Mount Sinai Million Health Discoveries Program
The current lack of diversity in genomic research data is hindering what we can learn about health and potential treatments in our global population. By enhancing the diversity of people participating in genomic research, we can advance our knowledge and discovery of human genetics for all populations. To that end, The Charles Bronfman Institute for Personalized Medicine is spearheading the effort to carry out the genetic sequencing of one million Mount Sinai patients within the next five years. This initiative, one of the largest such sequencing projects of its kind, will integrate health and research data at Mount Sinai to promote discoveries that will directly benefit our patient population. Access to the BioMe Biobank and Mount Sinai Million Biobank on HPC can be requested via the CBIPM Data and Specimen Inquiry Form. AIR·MS now features radiology metadata extracted from the Mount Sinai IRW 2.0 XNAT system (via an MSDW data pipeline). This data set is comprised of detailed DICOM (Digital Imaging and Communications in Medicine) tags associated with the medical images. These tags provide essential metadata, including patient information, imaging parameters, equipment details, and procedural context, ensuring a comprehensive understanding of each radiological study. By integrating this metadata, we enable researchers to gain deeper insights into the imaging data, facilitating advanced analyses and fostering innovations in medical imaging research. The following tables and attributes are available in AIR·MS:
Mount Sinai Million / BioMe identifiable (PHI)
Current Status
Schema: CDMMSM Data snapshot from 06/09/2025 Unique patients: 279,885
| PATIENT | Comments |
| ID | Internal ID for linking to other tables within the dataset |
| MRN | Medical Record Number (EPIC MRN – only accessible under regulatory approval) |
| MASKED_MRN | De-Identifier for combined BioMe Biobank set with Regeneron and Sema4 data |
| RGN_ID | De-identifier for first Regeneron batch regarding BioMe Biobank |
| SEMA4_ID | De-identifier for Sema4, a subset of Masked MRN ID |
| MSM_ID | De-identifier for Mount Sinai Million Biobank, a combined setoff RGN_ID and new MSM ID |
| MILLION_ID | Indicator for all consented patients with and without genomic data |
| AIR_CREATED_AT | Record creation in AIR·MS |
| AIR_UPDATED_AT | Record updated in AIR·MS |
Mount Sinai Million / BioMe de-identified (de-id)
Current Status
Schema: CDMMSMDEID Data snapshot from 06/09/2025 Unique patients: 279,885
| PATIENT | Comments |
| ID | Internal ID for linking to other tables within the dataset |
| MASKED_MRN | De-Identifier for combined BioMe Biobank set with Regeneron and Sema4 data |
| RGN_ID | De-identifier for first Regeneron batch regarding BioMe Biobank |
| SEMA4_ID | De-identifier for Sema4, a subset of Masked MRN ID |
| MSM_ID | De-identifier for Mount Sinai Million Biobank, a combined setoff RGN_ID and new MSM ID |
| MILLION_ID | Indicator for all consented patients with and without genomic data |
| AIR_CREATED_AT | Record creation in AIR·MS |
| AIR_UPDATED_AT | Record updated in AIR·MS |
Electrocardiogram (ECG) Data (PHI)
Electrocardiogram data, derived from Mount Sinai’s Cardiology Information System, is now available in AIR·MS.
Current Status
Data Source: GE HealthCare MUSE Cardiology Information System
Schema: CDMECG Data snapshot from: 04/10/2021 Unique patients: 1,961,254
The following tables and attributes are available in AIR·MS:
Number of records: 9,275,130
| PATIENT_DEMOGRAPHICS |
| PATIENT_DEMOGRAPHICS_ID (X) |
| FILE_ENTRY_ID |
| PATIENT_ID |
| PATIENTAGE |
| AGEUNITS |
| DATEOFBIRTH |
| GENDER |
| RACE |
| PATIENTLASTNAME |
| PATIENTFIRSTNAME |
Number of records: 9,168,266
| DIAGNOSIS |
| DIAGNOSIS_ID (X) |
| FILE_ENTRY_ID |
| MODALITY |
| DIAGNOSISSTATEMENT |
Number of records: 73,631,055
| LEAD_DATA |
| LEAD_DATA_ID (X) |
| FILE_ENTRY_ID |
| LEADBYTECOUNTTOTAL |
| LEADTIMEOFFSET |
| LEADSAMPLECOUNTTOTAL |
| LEADAMPLITUDEUNITSPERBIT |
| LEADAMPLITUDEUNITS |
| LEADHIGHLIMIT |
| LEADLOWLIMIT |
| LEADID |
| LEADOFFSETFIRSTSAMPLE |
| FIRSTSAMPLEBASELINE |
| LEADSAMPLESIZE |
| LEADOFF |
| BASELINESWAY |
| LEADDATACRC32 |
| WAVEFORMDATA |
Number of records: 9,610,935
| ECG_FILES |
| FILE_ENTRY_ID (X) |
| FILE_NAME |
| FILE_PATH |
| FILE_HASH |
| FILE_SIZE_BYTES |
| ACQUISITION_DATE |
| ACQUISITION_TIME |
| PROCESSING_STATUS |
| STATUS_CODE |
| NOTES_AND_COMMENTS |
| FILE_TIMESTAMP |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| JSON_STATUS |
Number of records: 9,168,230
| MUSE_INFO |
| MUSEVERSION |
| FILE_ENTRY_ID |
Number of records: 7,757,472
| ORDER_INFO |
| ORDER_INFO_ID (X) |
| FILE_ENTRY_ID |
| HISACCOUNTNUMBER |
| ORDERTIME |
| ADMITTIME |
| ADMITDATE |
| HISLOCATION |
| BED |
| ATTENDINGMDHISID |
| ATTENDINGMDLASTNAME |
| ATTENDINGMDFIRSTNAME |
| ALTERNATEVISITID |
| HISDISPOSITION |
| ADMITSOURCE |
| PRIMARYDIAGNOSTICCODE |
| SERVICINGFACILITY |
| ADMITTINGMDHISID |
| ADMITTINGMDLASTNAME |
| ADMITTINGMDFIRSTNAME |
| CONSULTINGMDID |
| REFERRINGMDHISID |
| HOSPITALSERVICE |
| ADMISSIONTYPE |
Number of records: 9,164,220
| ORIGINAL_DIAGNOSIS |
| ORIGINAL_DIAGNOSIS_ID (X) |
| FILE_ENTRY_ID |
| MODALITY |
| DIAGNOSISSTATEMENT |
Number of records: 9,168,044
| ORIGINAL_RESTING_ECG_MEASUREMENTS |
| ORIGINAL_RESTING_ECG_MEASUREMENTS_ID (X) |
| VENTRICULARRATE |
| ATRIALRATE |
| PRINTERVAL |
| QRSDURATION |
| QTINTERVAL |
| QTCORRECTED |
| PAXIS |
| RAXIS |
| TAXIS |
| QRSCOUNT |
| QONSET |
| QOFFSET |
| PONSET |
| POFFSET |
| TOFFSET |
| ECGSAMPLEBASE |
| ECGSAMPLEEXPONENT |
| QTCFREDERICA |
Number of records: 3,613,372
| PHARMA_DATA |
| PHARMA_DATA_ID (X) |
| PHARMARRINTERVAL |
| PHARMAUNIQUEECGID |
| PHARMAPPINTERVAL |
| PHARMACARTID |
| FILE_ENTRY_ID |
Number of records: 9,649,712
| QRS_TIMES_TYPES |
| GLOBALRR |
| QTRGGR |
| FILE_ENTRY_ID |
Number of records: 9,657,368
| RESTING_ECG |
| RESTING_ECG_ID (X) |
| FILE_ENTRY_ID |
| PATIENT_ID |
| ACQUISITIONDATE |
| ACQUISITIONTIME |
| STATUS |
Number of records: 9,167,778
| RESTING_ECG_MEASUREMENTS |
| RESTING_ECG_MEASUREMENTS_ID (X) |
| FILE_ENTRY_ID |
| VENTRICULARRATE |
| ATRIALRATE |
| PRINTERVAL |
| QRSDURATION |
| QTINTERVAL |
| QTCORRECTED |
| PAXIS |
| RAXIS |
| TAXIS |
| QRSCOUNT |
| QONSET |
| QOFFSET |
| PONSET |
| POFFSET |
| TOFFSET |
| ECGSAMPLEBASE |
| ECGSAMPLEEXPONENT |
| QTCFREDERICA |
Number of records: 9,654,325
| TEST_DEMOGRAPHICS |
| TEST_DEMOGRAPHICS_ID (X) |
| FILE_ENTRY_ID |
| DATATYPE |
| SITE |
| SITENAME |
| ACQUISITIONDEVICE |
| STATUS |
| EDITLISTSTATUS |
| PRIORITY |
| LOCATION |
| LOCATIONNAME |
| ROOMID |
| ACQUISITIONTIME |
| ACQUISITIONDATE |
| CARTNUMBER |
| ACQUISITIONSOFTWAREVERSION |
| ANALYSISSOFTWAREVERSION |
| EDITTIME |
| EDITDATE |
| EDITORID |
| REFERRINGMDLASTNAME |
| REFERRINGMDFIRSTNAME |
| ACQUISITIONTECHLASTNAME |
| EDITORLASTNAME |
| EDITORFIRSTNAME |
| SECONDARYID |
| HISSTATUS |
Intensive Care Unit (ICU) Data (PHI)
The Mount Sinai ICU Datamart is the world’s first ICU data platform designed to simultaneously support research, quality improvement, and operational initiatives. It is built on a common data model that standardizes critical care medical concepts, enabling consistent interpretation and integration of data across diverse ICU settings.The Mount Sinai ICU Datamart harmonizes and delivers high-fidelity information from all Mount Sinai adult ICUs with highly granular data available from 2011 onward and refreshed weekly. Beyond serving as a comprehensive data resource, it also tracks the evolution of the health system’s critical care landscape, capturing changes in unit specialties, geographic distribution, and the addition of new ICUs. By transforming the ICU’s inherently rich data environment into a standardized, dynamic, and accessible platform, the Mount Sinai ICU Datamart empowers clinicians, researchers, and administrators to advance data-driven care, operational excellence, and clinical discovery.
Current Status
Schema: CDMICU Number of patients: 103,974 Number of hospital admissions: 128,599 Number of ICU stays: 152,154 Number of clinical events and observations: 553,095,763
The following tables and attributes are available in AIR·MS:
Number of records: 128,600
| HOSP_ADMISSIONS |
| ADMISSION_LOCATION |
| ADMISSION_TYPE |
| ADMIT_PROVIDER_ID |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CREATED_INSTANT |
| DEATH_TIME |
| DISCHARGE_LOCATION |
| DISCH_TIME |
| ED_IN_TIME |
| ED_OUT_TIME |
| ETHNICITY |
| HADM_ID |
| HOSPITAL_EXPIRE_FLAG |
| INPATIENT_ADMIT_TIME |
| INSURANCE |
| LANGUAGE |
| MARITAL_STATUS |
| MODIFIED_INSTANT |
| RACE |
| SUBJECT_ID |
Number of records: 289,789,014
| HOSP_CHART_EVENTS |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CAREGIVER_ID |
| CHART_TIME |
| CREATED_INSTANT |
| HADM_ID |
| ITEM_ID |
| MODIFIED_INSTANT |
| STORE_TIME |
| SUBJECT_ID |
| VALUE |
| VALUE_NUM |
| VALUE_UOM |
| WARNING |
Number of records: 17
| HOSP_D_ITEMS |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CAREGIVER_ID |
| CHART_TIME |
| CREATED_INSTANT |
| HADM_ID |
| ITEM_ID |
| MODIFIED_INSTANT |
| STORE_TIME |
| SUBJECT_ID |
| VALUE |
| VALUE_NUM |
| VALUE_UOM |
| WARNING |
Number of records: 18,030
| HOSP_D_LAB_ITEMS |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CREATED_INSTANT |
| ITEM_ID |
| LABEL |
| MODIFIED_INSTANT |
Number of records: 263,306,749
| HOSP_LAB_EVENTS |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| COLLECTION_INSTANT |
| CREATED_INSTANT |
| FLAG |
| HADM_ID |
| ITEM_ID |
| LAB_EVENT_ID |
| LAB_ORDER_ID |
| MODIFIED_INSTANT |
| ORDER_PROVIDER_ID |
| PRIORITY |
| REF_RANGE_LOWER |
| REF_RANGE_UPPER |
| RESULT_INSTANT |
| SPECIMEN_TYPE |
| SUBJECT_ID |
| VALUE |
| VALUE_NUM |
| VALUE_UOM |
Number of records: 1,858,853
| HOSP_LDA_EVENTS |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CREATED_INSTANT |
| FIRST_RECORDED_INSTANT |
| ITEM_ID |
| LDA_ID |
| LENGTH_LDA |
| MODIFIED_INSTANT |
| PLACEMENT_INSTANT |
| REMOVAL_INSTANT |
| SUBJECT_ID |
Number of records: 63
| HOSP_LDA_ITEMS |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CREATED_INSTANT |
| ITEM_ID |
| LABEL |
| LDA_CATEGORY |
| LDA_SUB_CATEGORY |
| MODIFIED_INSTANT |
Number of records: 104,046
| HOSP_PATIENTS |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CREATED_INSTANT |
| DOB |
| DOD |
| EPIC_ID |
| ETHNICITY_COMBO_ID |
| GENDER |
| MODIFIED_INSTANT |
| PRIMARY_MRN |
| RACE_COMBO_ID |
| SUBJECT_ID |
Number of records: 525,267
| HOSP_PATIENT_SERVICES |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| ASSIGNMENT_END |
| ASSIGNMENT_START |
| CARE_UNIT |
| CARE_UNIT_ID |
| CREATED_INSTANT |
| HADM_ID |
| MODIFIED_INSTANT |
| PATIENT_SERVICE_ID |
| SUBJECT_ID |
Number of records: 839,542
| HOSP_TRANSFERS |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| BED_ID |
| CARE_UNIT |
| CARE_UNIT_ID |
| CREATED_INSTANT |
| EVENT_TYPE |
| HADM_ID |
| IN_TIME |
| MODIFIED_INSTANT |
| OUT_TIME |
| SUBJECT_ID |
| TRANSFER_ID |
Number of records: 152,154
| ICU_ICU_STAYS |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CARE_UNIT_ID |
| CREATED_INSTANT |
| HADM_ID |
| IN_TIME |
| LOS |
| MODIFIED_INSTANT |
| OUT_TIME |
| STAY_ID |
| SUBJECT_ID |
Number of records: 289,789,014
| ICU_ICU_STAYS |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CARE_UNIT_ID |
| CREATED_INSTANT |
| HADM_ID |
| IN_TIME |
| LOS |
| MODIFIED_INSTANT |
| OUT_TIME |
| STAY_ID |
| SUBJECT_ID |
Number of records: 30
| MAPPING_CARE_UNIT |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CARE_UNIT_END_DATE |
| CARE_UNIT_ID |
| CARE_UNIT_NAME |
| CARE_UNIT_START_DATE |
| CATEGORY_ID |
| CREATED_INSTANT |
| HOSPITAL_ID |
| MODIFIED_INSTANT |
Number of records: 29
| MAPPING_CARE_UNIT_SERVICE_TAG |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CARE_UNIT_ID |
| CREATED_INSTANT |
| MODIFIED_INSTANT |
| SERVICE_TAG_END_DATE |
| SERVICE_TAG_ID |
| SERVICE_TAG_START_DATE |
Number of records: 5
| MAPPING_CATEGORY |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CATEGORY |
| CATEGORY_ID |
| CREATED_INSTANT |
| MODIFIED_INSTANT |
Number of records: 47
| MAPPING_EPIC_DEPARTMENT |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CARE_UNIT_ID |
| CREATED_INSTANT |
| DEPARTMENT_ID |
| DEPARTMENT_NAME |
| EPIC_DEPARTMENT_END_DATE |
| EPIC_DEPARTMENT_START_DATE |
| MODIFIED_INSTANT |
Number of records: 336
| MAPPING_ETHNICITY |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CONCEPT_LEVEL_1 |
| CONCEPT_LEVEL_2 |
| CREATED_INSTANT |
| ETHNICITY_COMBO_ID |
| MODIFIED_INSTANT |
| RACE_ETHNICITY_TERMINOLOGY_KEY |
Number of records: 189
| MAPPING_ETHNICITY_BRIDGE |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CATEGORY_NAME |
| CREATED_INSTANT |
| ETHNICITY_COMBO_ID |
| MODIFIED_INSTANT |
Number of records: 38
| MAPPING_GEOGRAPHIC_LOCATION |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CARE_UNIT_ID |
| CREATED_INSTANT |
| GEOGRAPHIC_LOCATION |
| GEOGRAPHIC_LOCATION_END_DATE |
| GEOGRAPHIC_LOCATION_START_DATE |
| MODIFIED_INSTANT |
Number of records: 8
| MAPPING_HOSPITAL |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CREATED_INSTANT |
| HOSPITAL |
| HOSPITAL_ID |
| MODIFIED_INSTANT |
Number of records: 85
| MAPPING_PATIENT_SERVICE |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CREATED_INSTANT |
| MODIFIED_INSTANT |
| PATIENT_SERVICE |
| PATIENT_SERVICE_ID |
Number of records: 298
| MAPPING_RACE |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CONCEPT_LEVEL_1 |
| CONCEPT_LEVEL_2 |
| CREATED_INSTANT |
| MODIFIED_INSTANT |
| RACE_COMBO_ID |
| RACE_ETHNICITY_TERMINOLOGY_KEY |
Number of records: 176
| MAPPING_RACE_BRIDGE |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CATEGORY_NAME |
| CREATED_INSTANT |
| MODIFIED_INSTANT |
| RACE_COMBO_ID |
Number of records: 11
| MAPPING_SERVICE_TAG |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
| CREATED_INSTANT |
| MODIFIED_INSTANT |
| SERVICE_TAG |
| SERVICE_TAG_ID |
Radiology Metadata (PHI)
AIR·MS now features radiology metadata extracted from the Mount Sinai IRW 2.0 XNAT system (via an MSDW data pipeline). This data set is comprised of detailed DICOM (Digital Imaging and Communications in Medicine) tags associated with the medical images. These tags provide essential metadata, including patient information, imaging parameters, equipment details, and procedural context, ensuring a comprehensive understanding of each radiological study. By integrating this metadata, we enable researchers to gain deeper insights into the imaging data, facilitating advanced analyses and fostering innovations in medical imaging research.
Current Status
Schema: CDMRADIOLOGY Data snapshot from 8/16/2024 Unique patients: 2,057,482
The following tables and attributes are available in AIR·MS:
Number of records: 66,993,826
| RADIOLOGY_METADATA |
| ID |
| PATIENT_ID |
| SERIES_INSTANCE_UID |
| STUDY_INSTANCE_UID |
| ETL_RECORD_UPDATE_DATETIME |
Number of records: 7,745,407,087
| RADIOLOGY_DICOM_DATA |
| ID |
| RADIOLOGY_METADATA_ID |
| DICOM_TAGS |
| TAG_VALUE_REPRESENTATION |
| TAG_VALUE” NCLOB MEMORY |
| TAG_XTN_PATIENT_EPIC_MRN |
| TAG_PATIENT_NAME |
| SERIES_INSTANCE_UID |
| STUDY_INSTANCE_UID |
| ETL_RECORD_UPDATE_DATETIME |
Echocardiography Metadata (PHI)
AIR·MS contains DICOM metadata tags for cardiovascular imaging studies performed in the Mount Sinai Health System that are contained within the Softlink cardiovascular PACS system. This does not include radiology data contained within the radiology PACS systems. The following common modalities include US, CT, XA, NM, MR, IVUS. These modalities include, among others, echocardiographic ultrasound, vascular ultrasound, and angiographic data. These tags are linked to DICOM files by ECHO_METADATA.IMAGE_FILE_PATH in a repository on the Minerva cluster. Note that the schema name CDMECHO is a misnomer – this catalog contains much more than echocardiogram data.
The catalog contains every public DICOM metadata tag (dictionaries are publicly available, see https://dicom.innolitics.com/ciods for instance). The Tag is under ECHO_TAGS_DATA.TAGS and is labeled by its Name not its hexadecimal number for ease of readability (see https://www.dicomlibrary.com/dicom/dicom-tags/ for dictionary of public tags and name). The value of the tag is under ECHO_TAGS_DATA.TAG_VALUE.
Notes:
- As of late August 2025, there are known significant gaps in data availability around year 2019 and starting in mid 2023 and onward. The catalog ends in late 2023. Mechanisms for capturing missing data and updating the catalog moving forward are underway.
- There will be some duplicated data within the archive (i.e. 2 identical studies may be in 2 separate paths)
- There is a known bug in the way the value representation of “Person Name” is stored. It is stored as a list of single characters rather than a string (i.e. the name Smith is stored as [S,m,i,t,h])
Current Status
Schema: CDMECHO
Data snapshot from: 10/17/2023
Unique patients: 885,957
The following tables and attributes are available in AIR·MS:
Number of records: 268,682,931
| ECHO_METADATA |
| ID |
| FILE_ENTRY_ID |
| PATIENT_ID |
| SERIES_INSTANCE_UID |
| STUDY_INSTANCE_UID |
| SOP_INSTANCE_UID |
| IMAGE_FILE_PATH |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
Number of records: 21,089,507,788
| ECHO_TAGS_DATA |
| ID |
| FILE_ENTRY_ID |
| SERIES_INSTANCE_UID |
| STUDY_INSTANCE_UID |
| SOP_INSTANCE_UID |
| TAGS |
| TAG_VALUE |
| AIR_CREATED_AT |
| AIR_UPDATED_AT |
Endoscopy Reports (PHI)
AIR·MS contains a catalog of gastroenterology endoscopy reports stored in PDF format on Minerva. The reports are for a subset of these procedures wherein the reporting system transmits the reports as PDF files to Epic.
These are intended to be linked to the OMOP CDM via the latter’s person table. We do not currently link it to procedure records in procedure_occurrence. Various date fields related to the document and its transmission to the Epic system are available, but their validity can’t be guaranteed and filtering on those columns should be done with caution.
Number of records: 428,430
| REPORTS |
| FILE_ENTRY_ID: surrogate primary key; one row = one report |
| FILE_PATH: absolute path on Arion filesystem. Will be updated to be relative to gocryptfs mountpoint in a future release. |
| FILE_NAME: file name of report in PDF format |
| DOC_PT_ID: Epic ID; join to CDMPHI.PATIENT.XTN_EPIC_PATIENT_ID |
| EPIC_MRN: MSMRN; Epic ID; join to CDMPHI.PATIENT.XTN_PATIENT_EPIC_MRN |
| ORDER_PROC_ID: Epic Order ID |
| DOC_RECV_TIME: The date and time the document was received by Epic*. |
| SCAN_TIME: The date and time the document was scanned*. |
| DOC_SRVC_DTTM: The date and time the service described in the document was rendered*. |
* These columns are loaded from Epic, but their accuracy may vary based on a
variety of circumstances and cannot be guaranteed
Synthetic Public Use File (DE-SynPUF)
The SYNPUF (Synthetic Public Use Files) dataset, provided by the Centers for Medicare & Medicaid Services (CMS), offers a synthetic version of Medicare claims data from the years 2008 to 2010. This dataset is meticulously designed to maintain the statistical properties and relationships present in the original data while ensuring that no actual patient information is disclosed, thereby safeguarding privacy. SYNPUF includes a comprehensive array of variables such as beneficiary demographics, chronic conditions, hospital and outpatient claims, and prescription drug events, making it an invaluable resource for researchers and data scientists. It serves as an exemplary tool for developing and testing healthcare models, algorithms, and applications without the constraints associated with sensitive real-world data. The SYNPUF dataset in AIR·MS utilizes the OMOP Common Data Model, aligned with other clinical data sets available on the platform. Since SYNPUF data does not require an approved IRB, you can easily get onboarded and start building ML models!
Current Status
Schema: CDMSYNPUF Number of patients: 2,326,856 Number of observations: 37,531,051 Number of measurements: 72,387,791