
The Pondering Professor Series
In the first two posts of this series, I focused on two stages in a digital health study like CPP Tracker: the moment you’re deciding whether to join (and why we start with informed consent), and what actually happens to your data once you’ve said “yes.” For this third post, we will zoom out. Instead of walking through another step in the process, I want to ask a bigger question: What should you be able to expect from researchers who ask to use your health data? This question is increasingly relevant with the rapid expansion of apps, wearables, and smartphone‑based tools surrounding us.
Trust is built, not assumed
Digital health tools can collect a lot of information very quickly. In the case of our CPP Tracker study, that includes pains, flares, sleep, steps, mood, cycles, and more. The technology has outpaced most people’s mental model of where their data go and what happens next. In that environment, trust doesn’t come from having the “right” technical stack or the fanciest AI model. It comes from what people see and feel when they interact with you:
- Do they understand what you’re doing and why?
- Do your actions match what you said you would do?
- Do you admit limitations and uncertainties, rather than glossing over them?
- Do you respect their boundaries and decisions?
As a PI, I don’t think of trust as a vague, warm feeling. I think of it as something that is earned through a set of concrete behaviors over time.
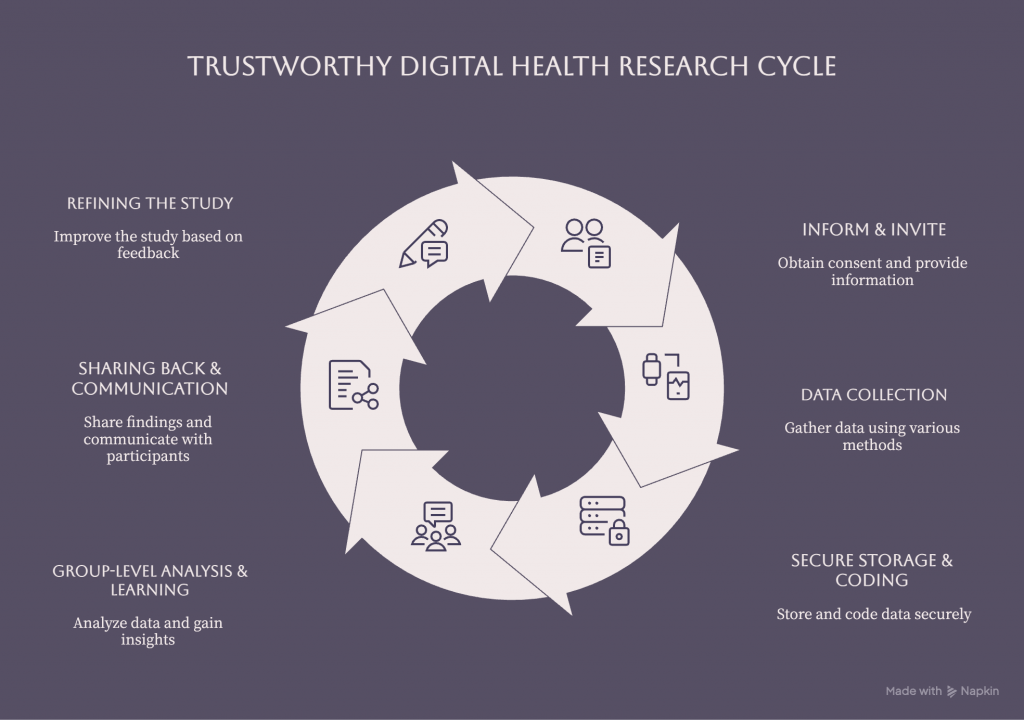
Trustworthy Use of Your Data in Digital Health Research
What participants should be able to expect
If we take trust seriously, then people who share their health data with us should be able to expect at least a few basics. Here is what I believe belongs on that list. You should be able to expect:
- Clarity. You can understand what the study is about, what you will be asked to do, and what will happen with your data.
- Purpose. Data collection feels connected to clear scientific questions, not like we are simply gathering everything we can “just in case.”
- Boundaries. Your data are used and shared only in the ways that are described in the consent materials and approved through the proper regulatory and institutional channels.
- Protection. Technical and procedural safeguards are in place to protect privacy and confidentiality, in line with institutional and regulatory requirements.
- Choice. You can say no, or change your mind later, without being penalized or losing access to clinical care or other services you would otherwise receive outside of that study.
- Responsiveness. When you ask questions or raise concerns, you get direct, honest answers.
- Respect. Your time, your energy, and your experiences are treated as valuable, not as something we are entitled to.
These are not about making a system risk‑free—that’s not realistic—but about building trustworthy systems where the way we handle risk is transparent and thoughtful, and where we don’t hide important details in fine print.
Research vs. “terms and conditions”
In Post 1 of this series, I talked about the difference between an informed consent process and the “I agree” box you see in many apps and wearables. That difference becomes even more important when we think about trustworthy data use. In a research study, the expectation is that we:
-
Define specific goals and methods,
-
Submit our plans to independent review,
-
Explain what we are doing in language you can understand, and
-
Invite you to make a free, informed choice about joining.
In many consumer contexts, you may see broad terms and conditions that:
-
Allow for open‑ended data use or sharing,
-
Can change with new versions of the app, and
-
Often appear when you’re just trying to get to the service you want to use.
That doesn’t mean all research is perfect or all companies are careless; reality is more complicated than that. But it does mean that the underlying model of agreement is different.
What this looks like in a study like CPP Tracker
In CPP Tracker, we ask participants to share information about chronic pelvic pain and related symptoms over time, often alongside app‑based or wearable‑based measures of daily life. The technical details live in our protocols, which are reviewed and approved by our IRBs and other compliance offices, but the values underneath them guide our everyday decisions. Some examples of how we try to translate “trustworthy use of data” into practice:
-
When we design our questionnaires and app prompts, we think carefully about what we are asking, how often, and why, so participation is meaningful but not overwhelming.
-
When we decide which data streams to include, we think not just about what is technically possible, but about what is scientifically justified and respectful of your privacy.
-
When we set up data storage and access, we use secure, approved systems and limit access based on people’s roles, not their curiosity.
-
When we plan analyses and publications, we keep the focus on group‑level patterns rather than shining a spotlight on individual stories without consent.
-
When participants or potential participants ask questions, we strive to answer them in plain language, even when the answer is “we don’t fully know yet, and this is part of why we’re doing the study.”
None of these things are glamorous. Most of them happen in the background and do not get any spotlight or headlines. But together, they help a digital health study feel like a trustworthy partnership.
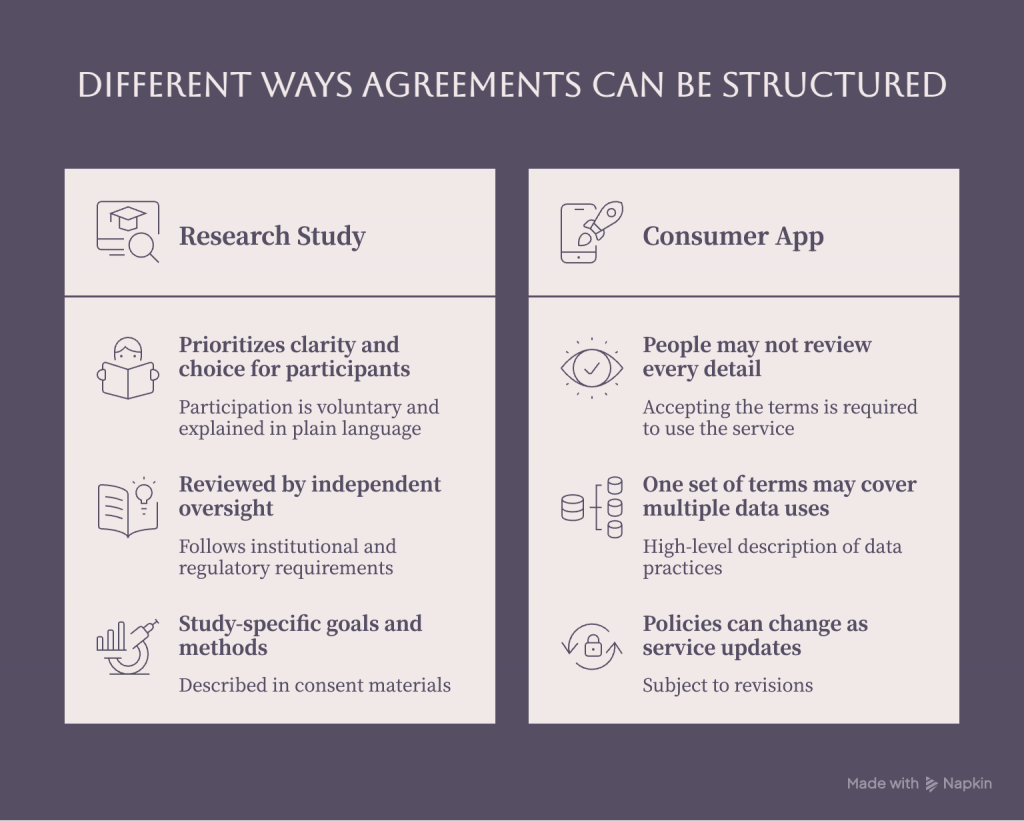
Different ways data agreements can be structured.
Trust in digital health is not just about data security
It’s natural to think about trust mainly in terms of security: encryption, firewalls, access logs, and so on. Those are critical, and they’re part of our everyday reality when we work with health data. But trust in digital health research also depends on factors that are less technical and more human, such as:
- Being honest about trade‑offs. For example, the more frequently we ask you to report symptoms, the richer the dataset, but also the more time and energy it costs you.
- Listening when people tell us something feels too invasive, too confusing, or too burdensome.
- Acknowledging history. Many communities have good reasons to be cautious about how institutions have used their health information in the past. We can’t erase that history, but we can let it inform how we show up now.
- Sharing back. Whenever possible, giving participants and communities access to what we’re learning, and in formats that are actually understandable, helps show that their contribution is valued.
Strong passwords and secure servers are necessary, but they’re not sufficient. Trustworthy use of health data requires both solid infrastructure and a consistent, participant‑centered way of thinking.
A future worth building toward
When I think about the future of digital health research, I hope a world where:
-
People understand enough about how their data might be used to make real choices,
-
Research participation feels like a partnership, not a transaction,
-
Digital tools are designed with privacy and respect in mind from the beginning,
-
The benefits of research reach the people whose data made it possible.
These are the principles that guide how we design and conduct our research studies. For conditions like chronic pelvic pain, endometriosis, fibroids, and other areas of women’s health that have been under‑studied and under‑served, we urgently need better data and better science. But we can’t afford to ignore the how while we chase the what. How we collect, protect, analyze, and talk about data is part of the science.
Closing: The Pondering Professor Corner
Across these three posts in The Pondering Professor Corner, we’ve moved from why we start with informed consent, to what happens to your data once you join a study, to what trustworthy use of health data should look like in digital health research. If there’s one idea I hope you carry with you, it’s this: digital health research depends on participant trust—and trust depends on clear, honest communication and responsible data stewardship. If you’ve shared your experience with us in CPP Tracker or any of our other studies: thank you. If you’re considering joining in the future, I hope this series helps you feel better equipped to ask questions, set boundaries, and decide what feels right for you.
This post is meant to give a general overview of how we think about trustworthy use of health data in studies like ours. It does not replace the specific consent form, HIPAA authorization, or study information you receive for any individual research study.
About the author: Ipek Ensari, PhD, is an Assistant Professor at the Icahn School of Medicine at Mount Sinai Department of AI and Human Health and principal investigator of the CPP Tracker study on chronic pelvic pain. Her research focuses on validation and reliability evaluation of data from wearables and apps, with a focus on women’s health and conditions like endometriosis, adenomyosis, and fibroids. Her recent talks and writings cover accuracy and reliability of digital health data and AI methods for women’s health, and how to responsibly use wearable and smartphone data in clinical research and real‑world settings.