
The Pondering Professor – Reflections on digital data and trust from PI Ipek Ensari
In the first post of this series, I talked about why we start with a consent form and what we are really asking of you when we invite you to join a digital health study like CPP Tracker. Once you say “yes,” the next question I hear a lot is simple and very reasonable: What actually happens to my data now?
When we’re talking about phone apps (like our ehive app), wearables, and real‑time symptom tracking, that question matters even more. You’re not just answering a one‑time paper survey; you’re sharing pieces of your daily life over time, and you deserve a clear picture of where that information goes and how we handle it.
The kinds of data we collect and why
In digital health research, the exact data we collect depend on the study, but in CPP Tracker and similar projects, it often includes:
-
symptom reports (for example, pain levels, fatigue, mood, or other pelvic symptoms)
-
short questionnaires about how symptoms affect daily life
-
timing information (when symptoms flare, how often they occur)
-
in some studies, data from wearables or phone sensors (such as activity or sleep patterns)
We collect these data because they help us understand your real‑world experience in a way we simply can’t capture in a single lab or clinic visit. For conditions we specialize in—like endometriosis, fibroids, and adenomyosis—where there is substantial unpredictability, this may include:
-
how your symptoms change across days, weeks, or cycles
-
how they interact with sleep, activity, or stress
-
how much your pain interferes with things you need and want to do
That’s where mHealth apps, wearables, and patient‑generated data become powerful tools in digital health research. They let us see patterns that can inform better care, earlier recognition, and more targeted interventions down the line.
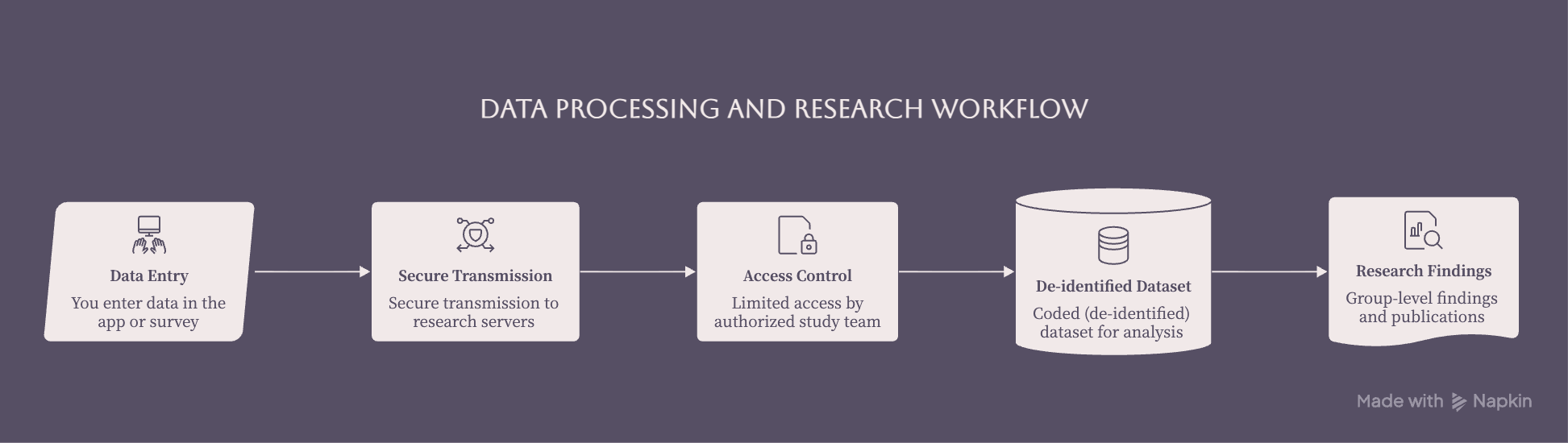
In CPP Tracker and our other digital health studies, your information moves through a defined path—from app entry to secure storage to de‑identified, group‑level analysis, rather than “floating around” without structure.
Where your data go
Behind the scenes, the path typically looks something like this:
You enter information into the app or survey.
- That information is securely transmitted to a research database or server approved for this purpose.
- Only authorized members of the study team can access identifiable data.
- For analysis, we usually work with coded (de‑identified) datasets.
- We look for patterns across participants, not for ways to “profile” any one individual.
In other words, once your information enters our systems, it’s not just floating around. It lives inside a structured research environment with rules, approvals, and technical safeguards that follow Mount Sinai’s policies and regulatory requirements. For me as PI, this is where health data privacy and research integrity meet: we can’t do meaningful digital health research without your data, and we should never forget that your data are pieces of your life, not just rows in a spreadsheet.
Who can see your data
You might be wondering: “If I join, does everyone at the hospital see my information?” The short answer is no. Typically, only study team members who need to see identifiable information to do their job on that study can access it. People working on data analysis usually see coded data (data labeled with a study ID instead of your name or other direct identifiers). Access is controlled and role‑based—not everyone in the department or on the grant can log in “just to look around.” From a technical point of view, there are multiple layers of access control and security. From a people point of view, our team includes clinical research coordinators, IT professionals, and engineers who are trained in privacy, confidentiality, and secure data handling, in line with Mount Sinai’s IRB and HIPAA‑related requirements.
What we are allowed to do with your data
This is where the consent form and the data pipeline come together. When you join a study, the information you receive should clearly explain:
-
the main questions the study is trying to answer
-
the types of data we’ll collect to answer those questions
-
how your information may be used during and after the study
-
whether de‑identified data might be used in future analyses or shared with other researchers
In our lab, that means:
-
We use your data to answer the specific research questions described in the study materials and approved by the IRB.
-
If we plan to use de‑identified data later or share them with collaborators or secure research repositories, we say so in the consent process.
-
We do not use your individual research data to make decisions about your employment, housing, or other non‑research services.
In sum, we use and share your information only as described in the consent form, in accordance with Mount Sinai policies, and as required or permitted by law. As part of the consent process, we explain whether any data sharing is planned, with whom, and for what purpose. You always have the choice to say yes or no to that participation without affecting your access to clinical care or other services you would otherwise receive. This kind of specific, informed agreement is very different from the broad “terms and conditions” you often see in consumer apps and wearables, where data use can be much more open‑ended.
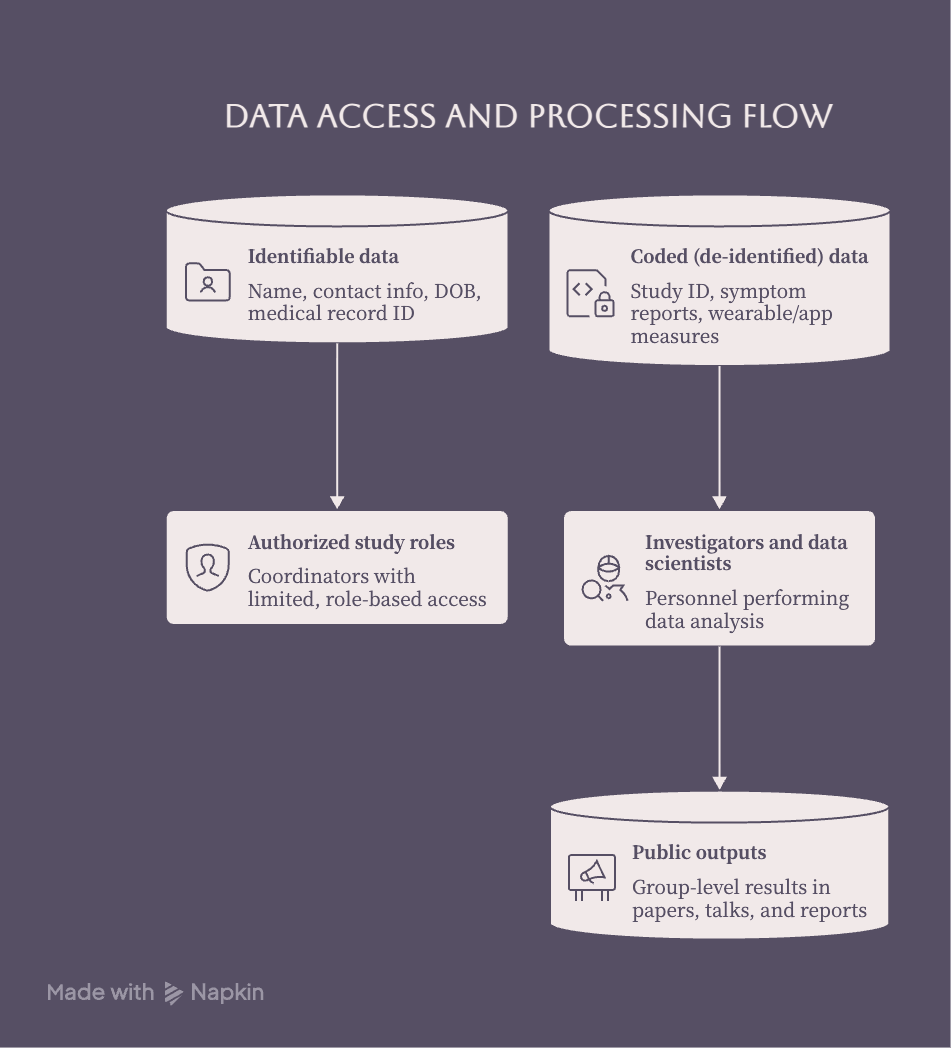
Identifiable information is limited to specific study roles, while investigators mainly work with coded (de‑identified) datasets and report only group-level results—not individual stories
How this looks in CPP Tracker
In our CPP Tracker study, participants share repeated reports of chronic pelvic pain and related symptoms over time. When your data come into the system:
-
They are stored in secure research databases, not on personal laptops or random shared drives.
-
Only the study personnel who need access for CPP Tracker work have it.
-
For most analyses, we use coded (de‑identified) datasets where we look at patterns across many participants rather than singling out individuals.
When we publish results, we talk about groups, not identifiable individuals. For example, we might report:
-
how symptom severity tends to change over time
-
how common certain symptom clusters are
-
how pain patterns relate to sleep or activity at a group level
Your data contribute to those patterns, but your personal story is not presented as a case report with your name attached. It is part of a larger picture that we are trying to understand so we can improve women’s health and chronic pelvic pain care more broadly.
What happens when the study ends
Another good question is: “What happens to my data after the study is over?” In most research, data are not deleted the moment the last participant finishes the last survey. We usually need to:
- finish the planned analyses
- verify and clean the dataset
- satisfy audit or regulatory requirements
- sometimes perform additional analyses that were described in the original plan
How long data are kept and for what purposes depends on the study, the approvals, and what you were told in the consent materials, as well as institutional and regulatory requirements. If de‑identified data are placed in a repository or used for future work, that should also be explained ahead of time. From my perspective as a PI, this is another place where transparency matters. You shouldn’t have to guess what “after the study ends” means for your information.
Why this matters for trust
You probably don’t want to know the names of our servers or the exact security protocols we use—and that’s okay. What I do want you to know is that:
-
your health data are handled inside a structured research system
-
access is limited and purposeful
-
analyses focus on patterns, not on judging individuals
-
data use is tied to what you were told and what you agreed to, and follows Mount Sinai and regulatory requirements
For me, that’s the minimum we owe our participants in digital health research. If we’re asking you to share continuous, sensitive information from your phone or wearable, we need to be clear and specific about what happens next.
Closing: The Pondering Professor Corner
In Post 1 of The Pondering Professor Corner, we stayed at the moment of decision: the consent form, and what I am asking of you when I invite you into a study like CPP Tracker. Here, we’ve followed your data one step further, into the research systems where they are stored, accessed, and analyzed. In the final post of this series, I’ll zoom out and talk about what I think trustworthy health data use should look like in digital health: what you should be able to expect from us, and how we can build a more transparent, participant‑centered future.
Because digital health research depends on participant trust—and trust depends on clear communication.
This post is meant to give a general overview of how research data are handled in studies like ours. It does not replace the specific consent form, HIPAA authorization, or study information you receive for any individual research study.