
SAP HANA In-Memory Database
What is SAP HANA?
![]() SAP HANA (High-performance Analytical Appliance) is an in-memory database platform developed by SAP SE. It uses in-memory computing to store data primarily in RAM, unlike traditional relational databases that need to retrieve data from disk-based storage solutions. With this technological innovation, SAP HANA can access in-memory data 10,000 times faster than data stored on standard disks. The result is that companies can now rapidly analyze large amounts of data and process transactions in seconds rather than hours.
SAP HANA (High-performance Analytical Appliance) is an in-memory database platform developed by SAP SE. It uses in-memory computing to store data primarily in RAM, unlike traditional relational databases that need to retrieve data from disk-based storage solutions. With this technological innovation, SAP HANA can access in-memory data 10,000 times faster than data stored on standard disks. The result is that companies can now rapidly analyze large amounts of data and process transactions in seconds rather than hours.
SAP HANA is the platform for SAP’s Enterprise Resource Planning software (S/4HANA) as well as other business applications and can run on-premises, in the cloud or in a hybrid configuration. Enterprises that have migrated over to SAP HANA have been able to realize accelerated business processes, improved data insights, and simplified IT environments.
Since SAP HANA can run both OLTP and OLAP workloads, it eliminates the need to move data to another database to run analytical applications. This removes the burden of maintaining separate legacy systems, data silos and data warehouses. The result is less data redundancy, a smaller hardware footprint and less data management costs as well. SAP HANA analyzes live data for real-time business decisions and analytics, using advanced data processing engines for business, text, spatial, graph and series data.
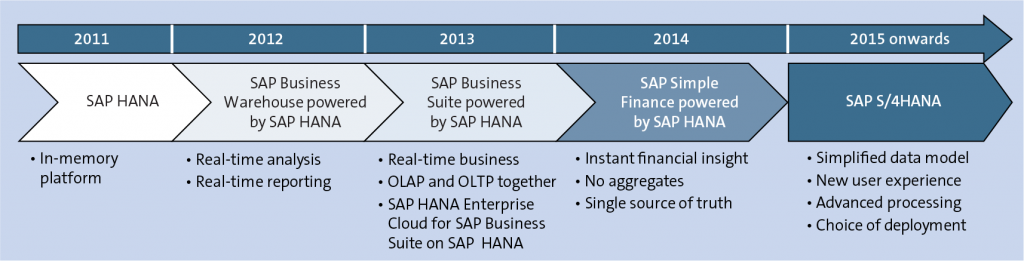
The initial version of the SAP HANA database was released to select customers in late 2010. SAP later debuted the general release at SAPPHIRE NOW, SAP’s annual technology conference in Orlando, FL in June 2011. SAP HANA made history as the first in-memory database in the world. It was an extremely popular product release, quickly becoming SAP’s fastest-adopted solution. Today there are over 30,000 customers utilizing SAP HANA.
SAP HANA Platform
While SAP HANA is mostly recognized for its ability to process large amounts of data at record speeds, it is far more than just an in-memory database.
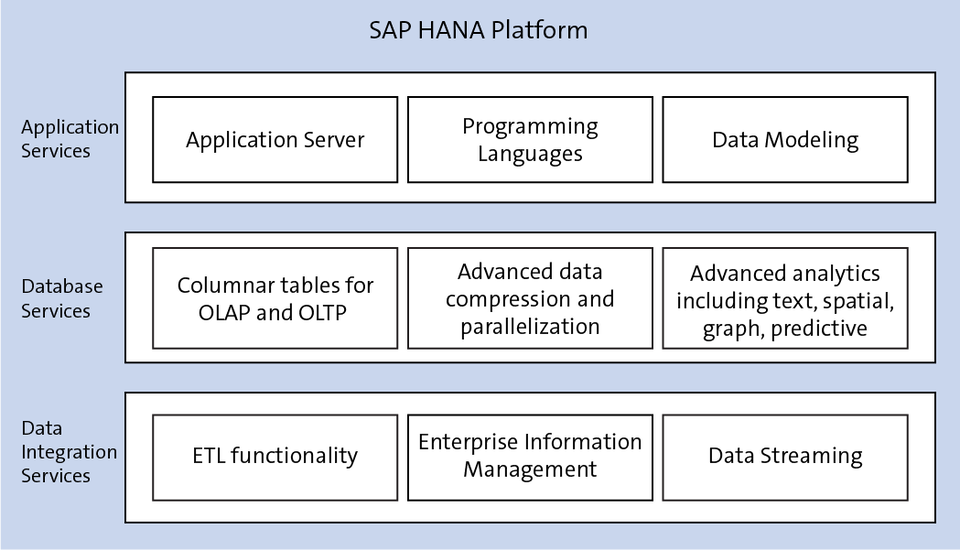
SAP HANA offers both column and row-based storage, making it capable of handling both OLTP and OLAP workloads. Tables that are organized in columns are optimized for high performing read operations while still providing good performance for write operations. In addition, column store offers extremely efficient data compression, which in turn saves memory and speeds up searches and calculations. Typical compression rates are 7x or greater when compared with a traditional RDBMS. Other column store features include table partitioning (which can further improve performance by utilizing partition pruning), and a delta store to optimize write operations.
Another technology built into the platform includes dynamic tiering, allowing for a temperature based (hot/warm/cold) data aging strategy. The purpose of this feature is to extend SAP HANA memory with a disk-centric columnar store for less frequently used data.
In addition, SAP HANA offers data integration services, high availability and disaster recovery capabilities, and a complete development platform known as SAP HANA XSA (SAP HANA extended application services, advanced model) that can be used to code with Java and Node.js. It includes OData support and is the successor to the now-deprecated XS classic model. Apps that were created with SAP HANA XS can be ported over to SAP HANA XSA.
The SAP Web IDE for SAP HANA is a browser-based integrated development environment used to create web-based and mobile user interfaces, business logic, and advanced data models. It provides a handful of developer tools, including syntax-aware code editors, inspection tools, debugging tools, and CDS modeling capability.
SAP HANA and Machine Learning
 Python Machine Learning Client for SAP HANA
Python Machine Learning Client for SAP HANA
Welcome to Python machine learning client for SAP HANA (hana-ml)!
This package enables Python data scientists to access SAP HANA data and build various machine learning models using the data directly in SAP HANA. This page provides an overview of hana-ml.
Python machine learning client for SAP HANA consists of two main parts:
- SAP HANA DataFrame, which provides a set of methods for accessing and querying data in SAP HANA without bringing the data to the client.
- A set of machine learning APIs for developing machine learning models.
Specifically, machine learning APIs are composed of two packages:
- PAL package
PAL package consists of a set of Python algorithms and functions which provide access to machine learning capabilities in SAP HANA Predictive Analysis Library(PAL). SAP HANA PAL functions cover a variety of machine learning algorithms for training a model and then the trained model is used for scoring. - APL package
Automated Predictive Library (APL) package exposes the data mining capabilities of the Automated Analytics engine in SAP HANA through a set of functions. These functions develop a predictive modeling process that analysts can use to answer simple questions on their customer datasets stored in SAP HANA.
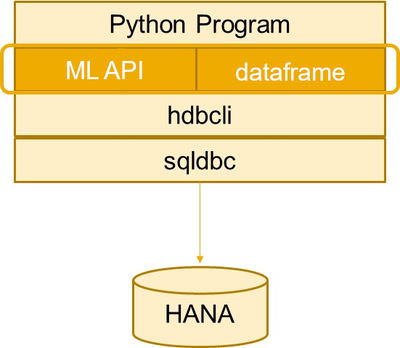
hana-ml uses SAP HANA Python driver (hdbcli) to connect to and access SAP HANA.
A figure of architecture is shown below:
For more information, see the Python Machine Learning Client for SAP HANA website.